About me…
I am researcher at Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas, Universidad Nacional Autónoma de México. I finished my Ph. D. in Computer Science at the Centro de Investigación en Computación, IPN. My research interests are in the field of natural language processing and text mining. I have worked on semantic similarity, authorship attribution, author profiling, and several text classification problems. During my Ph.D. I introduced text representation structures based on graphs to facilitate NLP tasks and a new method to calculate the semantic similarity between texts, called soft cosine similarity, which considers the semantic information of characteristics such as words, n-grams, POS tags, etc.
Curriculum Vitae
Dr. Helena Gómez Adorno is a professor of Artificial Intelligence at IIMAS-UNAM. Among her research interests areas are natural language processing, computational linguistics, and information retrieval; specifically, question answering, semantic similarity, authorship attribution, and author profiling. Lead a research and development team to implement intelligent systems with the help of machine learning and neural networks.
Awards and honours
- “ Lázaro Cárdenas 2019” Prize for remarkable performance as PhD. student in Engineering, Physical & Mathematical Sciences area from Instituto Politécnico Nacional.
- Award for the best academic performance of doctoral students of the Instituto Politécnico Nacional (IPN) 2016. There are approximately 50 doctoral students at the IPN. The diploma is awards to the best scores and publications.
- Scholarship “Award of Merit” for international students from the Ministry of Foreign Relations (SRE) of the Mexican Government for Master’s studies, 2011–2013. The SRE awards two scholarships per country by year.
- Best Paper Award for the work entitled “Author Profiling with doc2vec Neural Network-Based Document Embeddings” of the 15th Mexico International Congress of Artificial Intelligence (MICAI) 2016.
Research stays
- Instituto de Ingeniería - UNAM (Mexico), February - July 2018.
- IBM Deutschland Research and Development GmbH (Germany), July - September 2017.
Interests
- Artificial Intelligence
- Natural Language Processing
- Database
- Machine Learning
- Text Mining
Education
Service: COVID-19 in Twitter México · UNAM Posgraduate adviser · UNAM Social Service Program · NLP Summer School 2020 · MEX-A3T Workshop 2020 · Summer School on Digital Humanities 2023 · Macroentrenamiento en Inteligencia Artificial MeIA 2023 ·
Teaching
 Maestría en tecnologías de la información y la comunicación, 2016 - 2017
Maestría en tecnologías de la información y la comunicación, 2016 - 2017 Universidad Nacional de Asunción
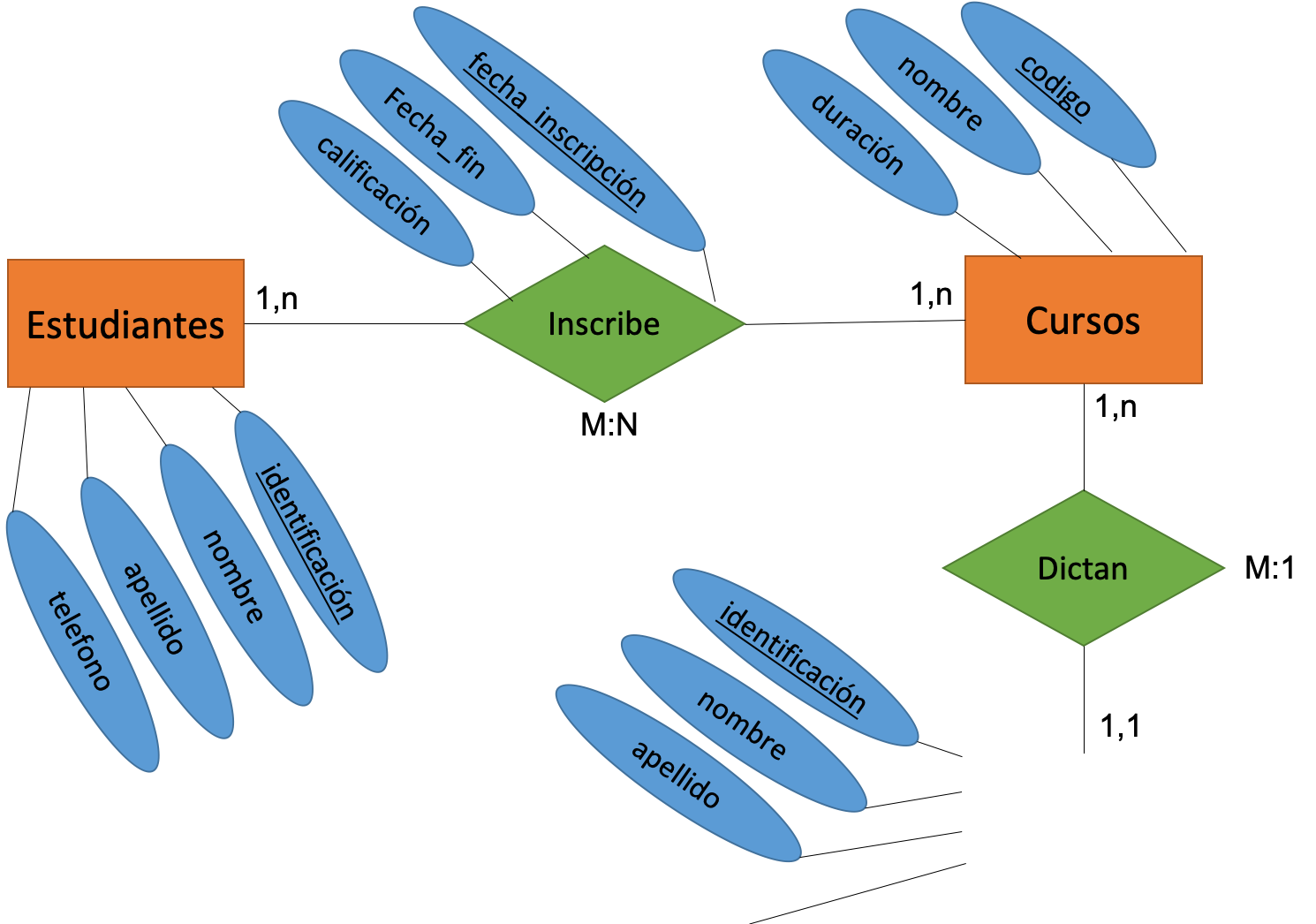 Curso de administración y programación de Base de datos., 2009 - 2011
Curso de administración y programación de Base de datos., 2009 - 2011 Universidad Nacional de Asunción
 Curso de Procesamiento de Lenguage Natural de la Licenciatura en Ciencia de Datos,
Curso de Procesamiento de Lenguage Natural de la Licenciatura en Ciencia de Datos, Universidad Nacional Autonoma de México (UNAM)
Team
Master Students
Past Students
Social Service Students
Projects
SIHSedesa: Hospital Information System - SEDESA
PAPIIT TA100520: Authorship analysis on documents with deep learning techniques.
CONACYT Project 298036: Feria de Talleres Mexicanas del Futuro: Trazando conciencias, pensando en TI Edición IIMAS UNAM.

Students seeking mentoring in Natural Language Processing may contact me to discuss the possibility. I work closely with the Linguistic Ingeniering group.